Contents
Overview
Cistern is an event aggregation and indexing system. Cistern consumes VPC Flow Logs and JSON events from AWS CloudWatch Logs and exposes a SQL-like querying interface.
Getting Started
First, download a release from GitHub. Cistern has no external dependencies and is a single binary.
Cistern accepts a few command-line flags.
- api-addr: Listen address for the UI and API (defaults to
localhost:2020) - config: Path to the config file (defaults to
./cistern.json) - data-dir: Data directory where Cistern saves data (defaults to
./data/) - ui-content: Path to static UI content (enables UI)
You’ll have to create a config file in order to let Cistern know which CloudWatch log groups to consume from.
Config file
The config file has two main options:
- cloudwatch_logs: A list of CloudWatch Logs log groups to consume.
- retention: The retention of events in days.
{
"cloudwatch_logs": [],
"retention": 3
}
You can specify the log groups to consume in the config file.
In the cloudwatch_logs section, add an object for each log group
with the name and whether it’s a flow log group.
Example
{
"cloudwatch_logs": [
{
"name": "flowlogs",
"flowlog": true
},
{
"name": "applogs",
"flowlog": false
}
],
"retention": 3
}
Credentials
Cistern will try to use AWS credentials from the following locations:
- Environment variables (AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY)
- Shared credentials file (~/.aws/credentials)
- EC2 Instance Role credentials
To specify the region, set the AWS_REGION environment variable.
Using Cistern
UI
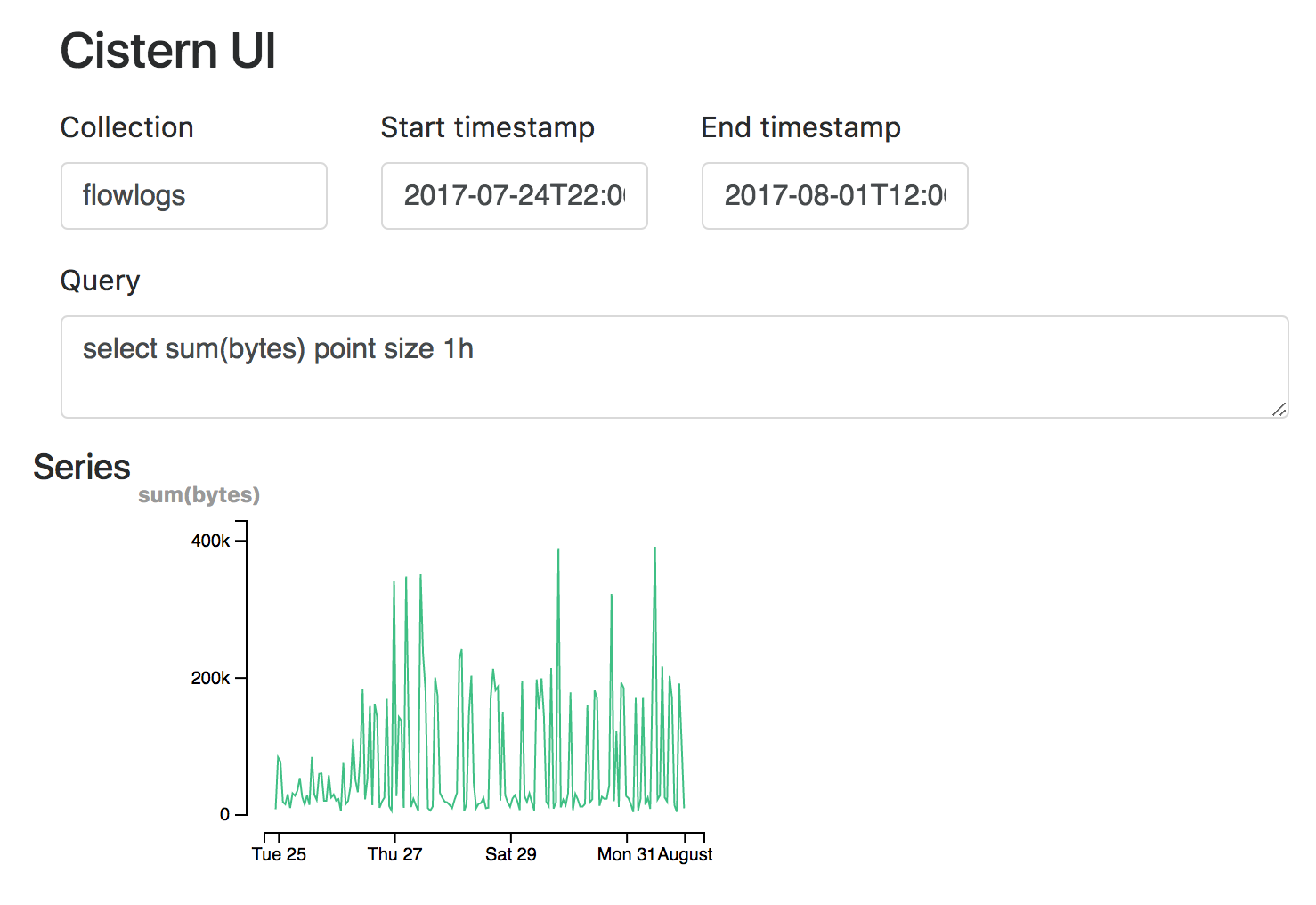
Cistern comes with a simple UI to query events. It’s accessible at
http://api-addr/ui/, where api-addr is the value of the command-line flag.
UI Screenshot:
Query Language
Cistern uses a SQL-like query language. Here’s an example:
SELECT sum(bytes), sum(packets)
GROUP BY source_address, dest_address
FILTER source_address neq "10.0.0.1"
ORDER BY sum(bytes) DESC
LIMIT 5
POINT SIZE 1h
You’ll notice that FILTER and POINT SIZE are keywords that aren’t from SQL.
The main components of that query are:
- SELECT
- GROUP BY
- FILTER
- ORDER BY
- LIMIT
- POINT SIZE
These six components must be in that order. All components are optional. The following sections of the documentation describe how the results change depending on which components are present.
Events
Raw events are returned if only FILTER and LIMIT are defined.
Aggregations
Aggregations are returned when there are aggregation columns defined with SELECT.
Time Series
Time series are returned when the POINT SIZE is defined. The argument passed
to POINT SIZE is a decimal number with a unit suffix. Valid time units are
ns, us (or µs), ms, s, m, h. If you need to set a point size
of 1 day, use 24h.
Filters
Filters are applied as the first stage of query execution. A filter requires a column name, a condition, and a value for the condition. The supported conditions are:
- eq: equal
- neq: not equal
If multiple filters are specified, they are applied in a boolean “AND” operation.
Retention
Cistern doesn’t enforce retention automatically. You’ll have to do it manually
by sending a POST request to the /api/collections/:collection/compact endpoint.
This will rewrite the collection and remove expired events.